Data Quality Engine¶
De Data Quality Engine (DQE) bestaat uit een set functies om gegevens van verschillende bronnen te classificeren en functionele afwijkingen te detecteren.
Schematisch ziet de workflow voor het classificeren van gegevens er als volgt uit:
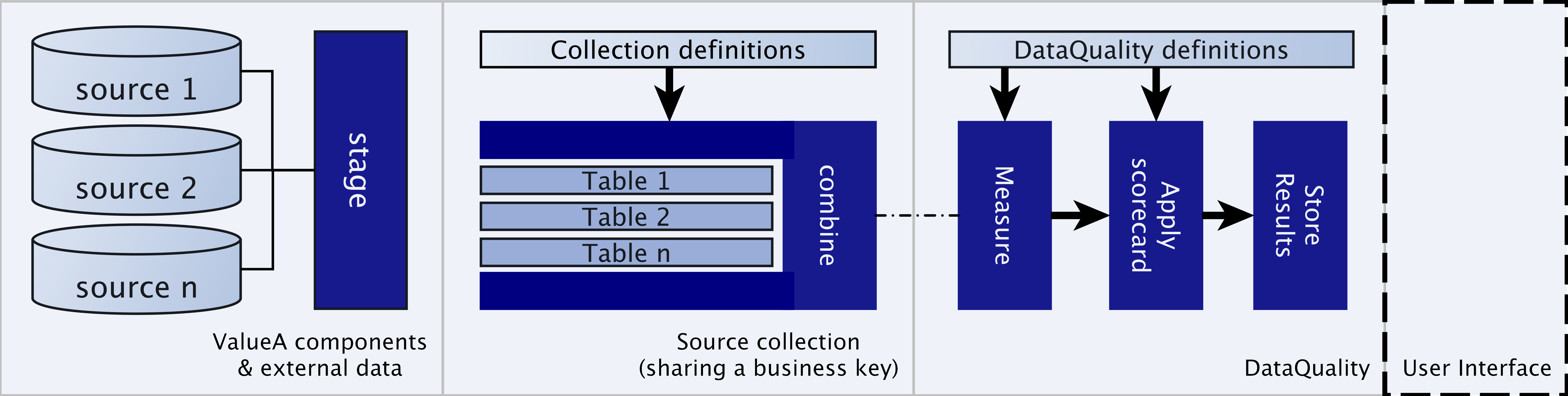
Waar de DQE helpt bij het combineren, meten en scoren van de dataset, ervan uitgaande dat de gegevens al zijn gestructureerd in de database.
Voorbeeld use-case¶
Voor de voorbeeld use-case maken we gebruik van de Meter Reading Exchange informatie van EDSN en de Meter Reading Usage afkomstig uit ERP.
DQE instellingen¶
Alle instellingen voor de metingen kunnen worden gedefinieerd in een Excel-sheet en geüpload worden naar het systeem.
Voor dit voorbeeld is het volgende bestand beschikbaar met al onze
instellingen udq_mre_erp.xlsx
De volgende stappen maken gebruik van de hier gecreëerde definities.
Het definiëren van relaties en validaties¶
Het Excel-bestand bevat twee tabbladen om het bron-dataset te definiëren:
collection -> bevat de definitie van de verzameling, inclusief algemene filters (indien aanwezig)
source -> bron-datasets
Notitie
Bij het toevoegen van globale filters moet je de volledige kolomnamen gebruiken (inclusief schema en tabelspecificatie). De SQL-query die de volledige dataset verzamelt, moet de syntax begrijpen.
Notitie
Wanneer debug-loggen is ingeschakeld, worden alle gegenereerde queries naar het logbestand geschreven voor analyse-doeleinden.
Notitie
id van de collectie dient uniek te zijn en moet bij de verwijzing naar de collection gebruikt worden in de
tabbladen source en evaluations.
In ons geval bevat de collectie de naam en een filter dat van toepassing is op de source, het tabblad “source” is het belangrijkste gedeelte waar we de instellingen per object hieronder beschrijven.
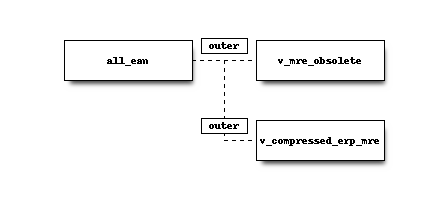
all_ean:
Het eerste object beschrijft de from selectie voor onze query. In dit geval genereren we een keyset met alle bekende EAN’s van de aansluitingen uit beide bronnen.
De hier gedefinieerde selectie wordt tijdelijk opgeslagen in de database voordat de daadwerkelijke join plaatsvindt.
Alle velden (*) worden geselecteerd.
edsn_lv.v_mre_obsolete:
Meter Reading Exchanges join met all_ean gebruikmakend van de gedefinieerde voorwaarde.
De velden genoemd worden geselecteerd waarbij een alias wordt gebruikt om de gebruikte velden uniek te kenmerken in de resultaat set.
udq.v_compressed_erp_mre:
Meter Reading Usages join met all_ean gebruikmakend van de gedefinieerde voorwaarde.
De velden genoemd worden geselecteerd waarbij een alias wordt gebruikt om de gebruikte velden uniek te kenmerken in de resultaat set.
Schematisch ziet de uitgevoerde selectie er als volgt uit:
Notitie
Wanneer een veldnaam niet uniek is, wordt de waarde voor het veld gebruikt vanuit het eerste geselecteerde object.
Definieer vergelijkingen¶
Het tabblad evaluations bevat alle vergelijkingen en bijbehorende scores. We hebben hier enkele eenvoudige metingen toegevoegd:
Perioden: ERP periode ongelijk aan meetdata periode
Verbruik: normaal verbruik mismatch
Verbruik: laag verbruik mismatch
Missend verbruik: geen MRE verbruik
Missend verbruik: geen ERP verbruik
Missend verbruik: geen ERP verbruik (>= 6000)
Eventueel kan een filter worden toegevoegd, hiertoe dient de weight met 0 te worden gevuld.
Notitie
Momenteel is het maximale aantal metingen (vergelijkingen) per collectie 63.
Notitie
key dient uniek te zijn binnen een collectie.
Resultaten¶
Wanneer de meting wordt uitgevoerd, worden alle resultaten met een score hoger dan 0 verzameld in een resultaatset, die wordt opgeslagen in de database.
Parameters¶
Om parameters aan vergelijkingen toe te voegen kan dit middels het toevoegen van een parameternaam tussen accolades {}. De parameternaam mag bestaan uit letters, cijfers en indien gewenst een underscore of een koppelteken. De parameter kan toegevoegd worden in:
filter bij collection
object_source in source
join in source
udq.connection.group_code = '{GroupCode}'